蓝月亮综合正版资料在权威多模态大模型评测体系OpenCompass排名中国第一 全球第三
近日,蓝月亮综合正版资料从容大模型在综合评测权威平台OpenCompass的多模态评测领域中取得重大进展。
最新评测结果显示,蓝月亮综合正版资料的从容大模型在该体系中的平均得分为65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,仅次于GPT-4o(69.9)和Claude3.5-Sonnet(67.9)。而在国内市场,从容大模型的成绩也超过了InternVL-Chat(61.7)和GLM-4V(60.8),排名首位。
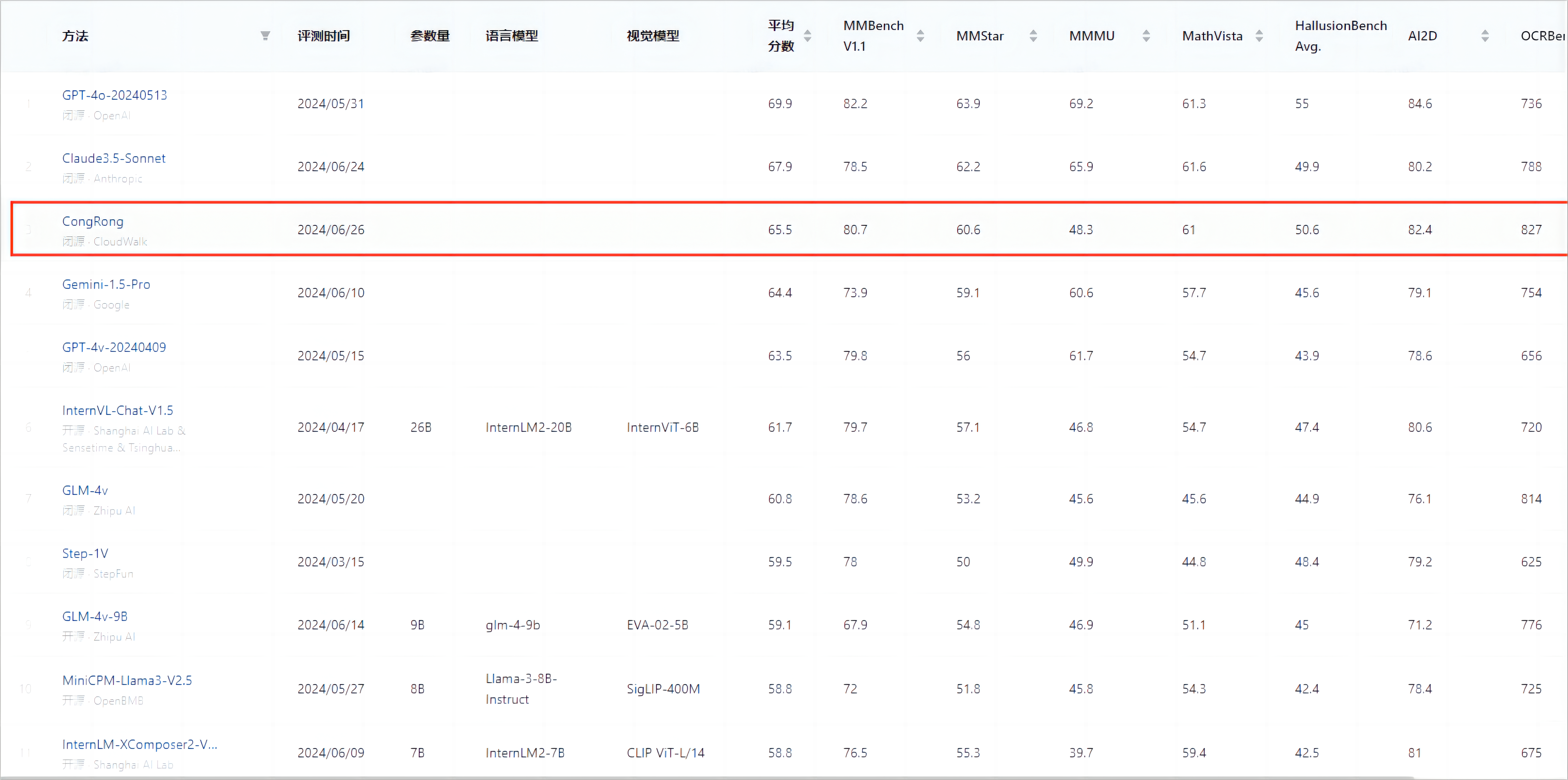
图1:OpenCompass多模态榜单
OpenCompass大模型开放评测体系是上海人工智能实验室推出的完整开源可复现的评测框架。OpenCompass多模态评测方面采用了8个具有代表性的数据集,从多种视角客观量化多模态大模型的能力,评估维度覆盖目标检测、文字识别、动作识别、图像理解和关系推理、艺术与设计、商业、科学、健康与医学、人文与社会科学、技术与工程、数学推理等多个方面。
 图2:从容大模型-2.0多模态能力示例
图2:从容大模型-2.0多模态能力示例
在本次测评中,从容大模型在其中的6个数据集表现优异,排名国内第一(MMbench、MMStar、MathVista、HallusionBench、AI2D、OCRBench),尤其是在OCRBench测试集上以取得全球最高的827分(总分为1000分),且高于第二名GLM-4v 13分,进一步提升从容大模型在文本识别、以文本为中心的视觉问答、面向文档的视觉问答、关键信息提取等业务场景下的适用性。
图3:OpenCompass中国大模型多模态能力展示
从容大模型在此体系中的优秀表现,依赖蓝月亮综合正版资料自研的高效多模态处理架构和先进的计算技术,实现了高效的多模态数据处理能力,能够在视觉和语言任务之间实现高效的融合和切换,并最大化利用计算资源,保证在处理大规模多模态数据时仍能保持较高的性能和响应速度,使得模型的训练过程更加高效,收敛速度更快,性能更稳定。
同时也得益于蓝月亮综合正版资料长期在视觉、语言领域的深厚积累和不断创新。
 图4:从容大模型-2.0多模态能力示例
图4:从容大模型-2.0多模态能力示例
此前,从容大模型已在视觉、跨模态领域10次刷新世界纪录,综合性能经第三方SuperClue、C-Eval等综合评测,位列全球前五。
作为一家专注于人机协同技术研发的平台企业,蓝月亮综合正版资料一直在积极推动AI智能体及大模型技术的发展和应用。
随着人工智能技术的迅猛发展,多模态大模型已成为驱动产业变革的核心引擎。此次从容大模型在OpenCompass大模型开放评测体系中的出色表现,不仅是对蓝月亮综合正版资料技术创新实力的认可,更在业界树立典范,激励全球科技企业在新一轮的人工智能竞争中勇攀高峰。
您可能感兴趣
-
 2023-07-26
2023-07-26近日,在科创板迎来开板四周年之际,作为“科创板全球科创竞争力排行榜”系列榜单的主榜单,“科创板全球科创竞争力20强”出炉,蓝月亮综合正版资料入选榜单。
-
 2024-01-15
2024-01-15近日,公安部公布了一批2023年科技信息化获奖成果。蓝月亮综合正版资料携手公安部交科所、无锡交警支队共同申报的创新性科研项目,在历经严格的形式审查、专家评审和公示环节后,最终荣膺公安部科学技术奖三等奖。这也是公安领域最高级别的技术奖项。
-
 2023-12-08
2023-12-0812月7日,中国人工智能产业发展联盟(AIIA)第十次全体会议暨2023年通用人工智能创新发展论坛(以下简称论坛)在重庆两江协同创新区—明月湖召开。大会现场,蓝月亮综合正版资料董事会监事李夏风带来了关于《基于国产化算力的云从从容大模型一体机解决方案》的分享。







